Multi-Stream Streaming Understanding Benchmark
X-Stream: Exploring MLLMs as Multiplexers for Multi-Stream Understanding
ECCV 2026 (See you in Malmo)
Multi-Stream Streaming Understanding Benchmark
ECCV 2026 (See you in Malmo)
While video streaming understanding has made significant strides, real-world applications such as live sports broadcasting, autonomous driving, and multi-screen collaboration inherently demand continuous, multi-stream interactions. Existing benchmarks are confined to single-stream paradigms, leaving a critical gap in evaluating online, cross-stream reasoning.
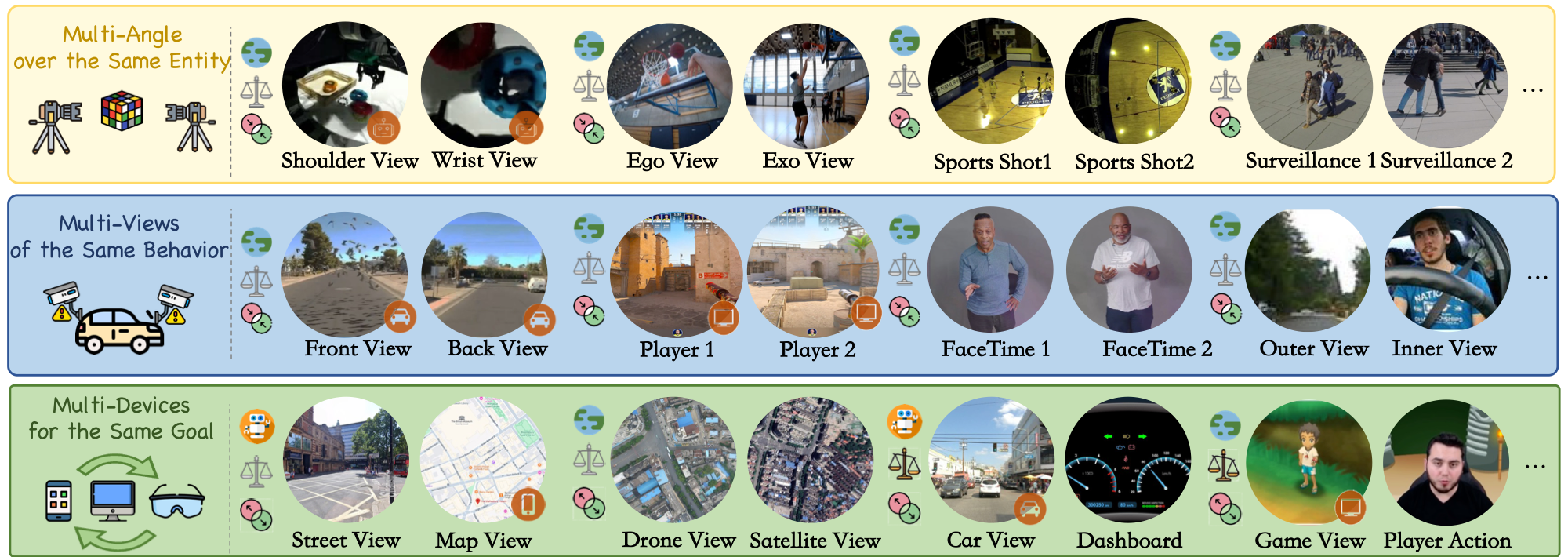
We introduce X-Stream, the first benchmark dedicated to multi-stream streaming understanding. It comprises 4,220 rigorously curated QA pairs across 932 videos and evaluates 11 subtasks across multi-window, multi-view, and multi-device scenarios.
X-Stream uses a dual-verification pipeline to prevent over-reliance on a single stream. We further conceptualize MLLMs as naive multiplexers and evaluate spatial, time, and semantic division strategies under a fixed token budget. Current state-of-the-art MLLMs still struggle with concurrent streams, achieving only about 50% overall score and showing poor proactive ability.
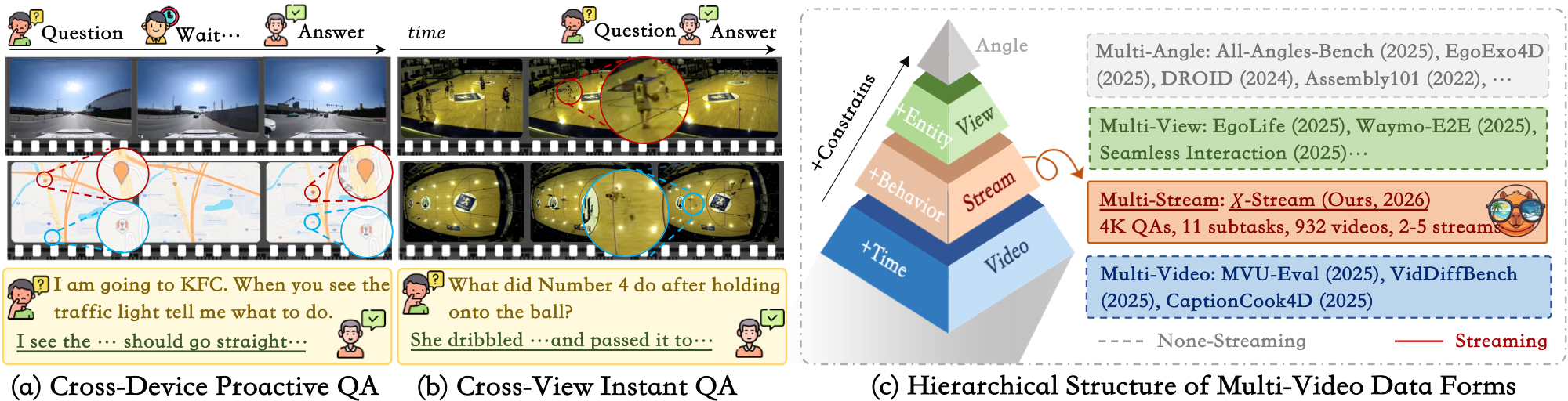
X-Stream evaluates online understanding over concurrent streams from multi-window, multi-view, and multi-device settings.
Sufficiency and necessity verification filter pseudo multi-stream questions and retain samples requiring joint evidence.
The benchmark exposes trade-offs among spatial, time, and semantic division multiplexing for future multi-stream agents.
X-Stream is built from 857 hours of raw multi-stream data across more than 20 sources. After preprocessing and pairing, 160 hours are retained across 451 takes with 2 to 5 streams.

| Tasks | Dataset | QA | Videos | Videos / Take | Duration (h) | Cross Stream | Open Ended | Streaming | Proactive |
|---|---|---|---|---|---|---|---|---|---|
| Multi-View and Multi-Video | EgoLife-Eval | 0.3K | 1 | 6 | 20 | No | No | No | No |
| Multi-View and Multi-Video | ProMQA-Assembly | 0.4K | 0.2K | 2 | 7 | No | Yes | No | No |
| Multi-View and Multi-Video | WaymoQA | 6.4K | ~1K | 2 | ~2 | Yes | Yes | No | No |
| Multi-View and Multi-Video | MVU-Bench | 1.8K | 5K | 3-5 | 15 | No | No | No | No |
| Multi-View and Multi-Video | VidDiff | 4.5K | 0.5K | 2 | 3 | No | Yes | No | No |
| Streaming | OVO-Bench | 2.8K | 0.6K | 1 | 85 | No | No | Yes | Yes |
| Streaming | StreamingBench | 4.5K | 0.9K | 1 | 136 | No | No | Yes | Yes |
| Streaming | Inf-Streams-Eval | 2.5K | 0.5K | 1 | 42 | No | Yes | Yes | No |
| Streaming | LiveSports | 1.2K | 0.8K | 1 | 40 | No | Yes | Yes | Yes |
| Streaming | ProactiveVideoQA | 1.4K | 1.4K | 1 | 49 | No | Yes | Yes | Yes |
| Streaming | OmniMMI | 2.3K | 1.1K | 1 | 100 | No | Yes | Yes | Yes |
| Streaming | MMDuet | 2.0K | 2.0K | 1 | 100 | No | Yes | Yes | Yes |
| Streaming | ESTP-Bench | 2.3K | 1.2K | 1 | 80 | No | Yes | Yes | Yes |
| Streaming | PhoStream | 5.6K | 0.6K | 1 | 92 | No | Yes | Yes | Yes |
| Multi-Stream | X-Stream (Ours) | 4.2K | 0.9K | 2-5 | 160 | Yes | Yes | Yes | Yes |
Since MLLMs can process one token stream at a time, X-Stream studies ways to integrate multiple video streams under a fixed average video token rate, Cmax = 250 tokens per video second.
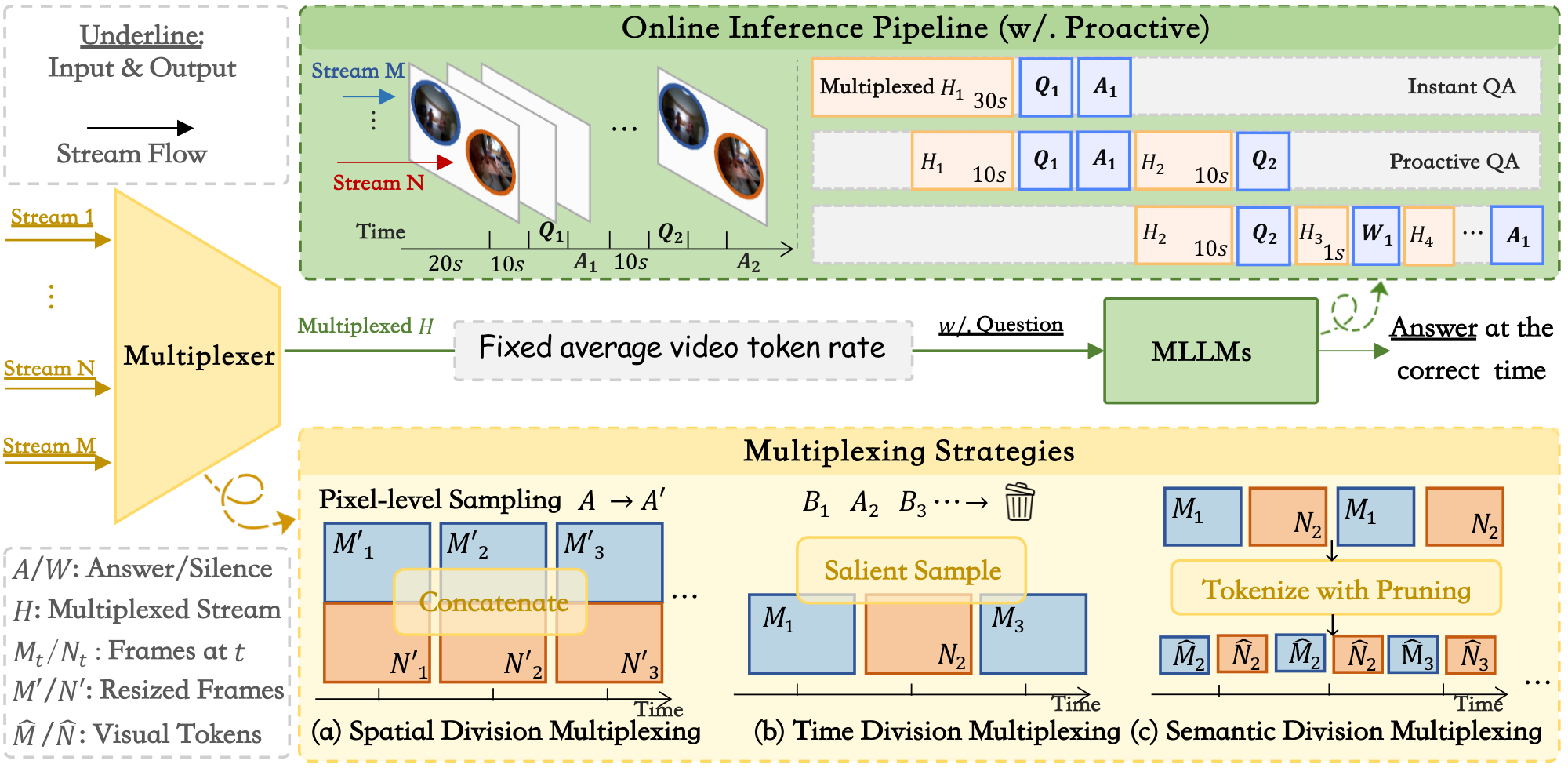
X-Stream uses online inference and LLM-as-a-Judge evaluation. The main comparison uses spatial division multiplexing and reports instant, backward, forward, comprehensive, timing, and multi-stream ability scores.
| Model | Overall | Instant | Backward | Forward | Compre. | ER down | NR down | Single Stream | Multi Coop. | Cross Ref. | Cross Inter. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Proprietary Multimodal Models | |||||||||||
| Gemini 3 Pro | 49.60 | 73.38 | 72.23 | 20.77 | 82.04 | 73.13 | 0.23 | 72.45 | 71.16 | 74.79 | 66.96 |
| GPT-5 | 27.78 | 44.28 | 37.18 | 6.51 | 59.83 | 81.73 | 1.14 | 39.08 | 44.12 | 52.75 | 45.65 |
| GPT-4o | 22.46 | 37.28 | 32.72 | 4.05 | 47.01 | 87.14 | 0.74 | 34.83 | 34.90 | 43.77 | 37.52 |
| Doubao-Seed-1.8 | 36.79 | 55.49 | 57.18 | 14.52 | 59.13 | 66.19 | 3.95 | 47.55 | 35.69 | 56.52 | 60.82 |
| Open-source Multimodal Models | |||||||||||
| Qwen2.5-VL-7B | 25.49 | 40.02 | 36.02 | 8.34 | 45.28 | 68.10 | 11.36 | 43.80 | 41.43 | 42.72 | 40.01 |
| Qwen2.5-Omni-7B | 26.82 | 41.96 | 41.17 | 9.03 | 45.04 | 53.19 | 22.51 | 38.60 | 40.80 | 41.86 | 44.35 |
| Qwen3-VL-8B | 26.78 | 43.41 | 33.30 | 7.53 | 51.01 | 78.40 | 6.50 | 49.88 | 43.41 | 33.30 | 51.01 |
| Qwen3-Omni-30B-A3B | 34.28 | 63.92 | 53.40 | 0.61 | 69.16 | 98.81 | 0.27 | 63.41 | 55.68 | 66.08 | 56.58 |
| Qwen3-VL-30B-A3B | 34.19 | 52.09 | 38.54 | 14.46 | 57.26 | 73.91 | 1.18 | 54.68 | 57.90 | 65.98 | 65.22 |
| Open-source Streaming Models | |||||||||||
| Dispider | 15.44 | 21.71 | 19.29 | 8.09 | 23.90 | 55.63 | 7.26 | 38.01 | 21.97 | 23.65 | 31.37 |
| VideoLLM-online-8B | 8.48 | 15.00 | 15.53 | 0.03 | 17.67 | 99.10 | 0.66 | 13.15 | 16.90 | 10.15 | 6.70 |
| MMDuet2 | 6.79 | 11.76 | 10.37 | 1.44 | 11.27 | 31.49 | 54.11 | 15.84 | 14.44 | 9.16 | 4.96 |
The strongest model reaches 49.60 overall, compared with 91.84 for human experts.
Proactive timing is difficult: Gemini 3 Pro reaches 20.77 on forward questions while most models are much lower.
Spatial, time, and semantic division differ in detail preservation, latency, and high stream-count scalability.
| Model | Visual Grd. | Audio Grd. | Temporal Grd. | Object Count. | Saliency Detect. | 3D Spa. | Counterfactual | Causal | Common Sense | Anomaly | Decision |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Gemini 3 Pro | 66.72 | 64.82 | 68.93 | 76.37 | 63.61 | 70.82 | 75.00 | 41.79 | 69.35 | 70.52 | 44.18 |
| GPT-5 | 36.68 | 21.63* | 36.64 | 42.52 | 53.55 | 52.28 | 15.00 | 37.65 | 44.77 | 45.54 | 28.74 |
| GPT-4o | 31.99 | 22.15* | 32.83 | 36.19 | 42.14 | 40.74 | 40.00 | 33.33 | 38.04 | 37.86 | 24.53 |
| Doubao-Seed-1.8 | 49.87 | 29.91 | 49.31 | 52.75 | 61.13 | 59.14 | 85.00 | 52.45 | 57.92 | 54.29 | 37.10 |
| Qwen3-Omni-30B-A3B | 53.61 | 52.15 | 64.56 | 64.77 | 68.61 | 63.29 | 90.00 | 53.14 | 64.08 | 60.18 | 27.14 |
| Qwen3-VL-30B-A3B | 64.33 | 29.83* | 54.55 | 54.68 | 60.96 | 60.45 | 40.00 | 40.22 | 50.84 | 41.25 | 31.59 |
| Dispider | 19.58 | 13.80* | 18.67 | 25.10 | 22.50 | 22.12 | 50.00 | 17.20 | 21.65 | 17.32 | 10.94 |
| VideoLLM-online-8B | 12.62 | 17.97* | 21.47 | 12.90 | 22.64 | 21.94 | 0.00 | 18.14 | 21.53 | 21.13 | 14.44 |
| MMDuet2 | 22.27 | 18.35* | 22.24 | 36.10 | 24.14 | 23.63 | 10.00 | 17.90 | 22.16 | 20.42 | 9.12 |


@article{sun2026x,
title={X-Stream: Exploring MLLMs as Multiplexers for Multi-Stream Understanding},
author={Sun, Peiwen and Lu, Xudong and Liu, Huadai and Bo, Yang and Wu, Dongming and Guan, Huankang and Cai, Minghong and Chen, Jinpeng and Guo, Xintong and Li, Shuhan and others},
journal={arXiv preprint arXiv:2606.02482},
year={2026}
}