|
I am a Researcher at BUPT, focused on machine learning for emotion/sentiment understanding and multimodal understanding. After completing my undergraduate studies at BUPT, I was recommended to pursue a master's degree in the Department of Artificial Intelligence at the same institution. I have worked closely with Honggang Zhang from BUPT, Di Hu from RUC, and Wei Xue from HKUST. I am heading to my PhD in the future. I used to be an intern at Megvii and Tencent to do research on multimodal understanding and generation.
|

|
|
🎉01/23/2025: 1 paper is accepted by ICLR 2025. See you in Singapore. 🎉12/10/2024: 1 paper is accepted by AAAI 2025. See you in Philadelphia. 🎉7/16/2024: 2 papers are accepted by ACM MM 2024. See you in Melbourne. 🎉7/1/2024: 3 papers are accepted by ECCV 2024. See you in Milan. |
|
2025: ICLR, CVPR, ICCV, IJCAI, ACM MM, ICASSP, COLING 2024: ICLR, CVPR, ECCV |
|
China National Scholarship (2024) MCM/ICM Finalist Award (2021) |
|
My research focuses on audio-visual learning and multi-modal machine learning, with the downstream tasks of person recognition and emotion/sentiment recognition techniques for video recognition, including the use of sound and images to learn better representations. |
|
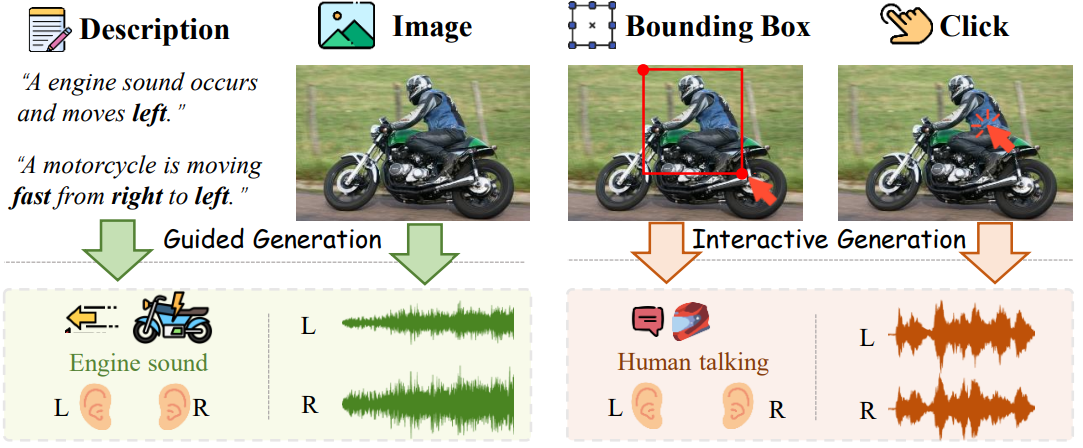
Peiwen Sun*, Sitong Cheng*, Xiangtai Li*, Zhen Ye, Huadai Liu, Honggang Zhang, Wei Xue, Yike Guo ICLR (Spotlight), 2025 Arxiv The pioneering work on language-driven spatial audio generation for controllable and immersive stereo audio. |

|
Peiwen Sun, Honggang Zhang, Di Hu ACM MM (Oral), 2024 Arxiv Unveiling and mitigating bias caused by real-world inherent preferences and distributions in Audio Visual Segmentation. |
|
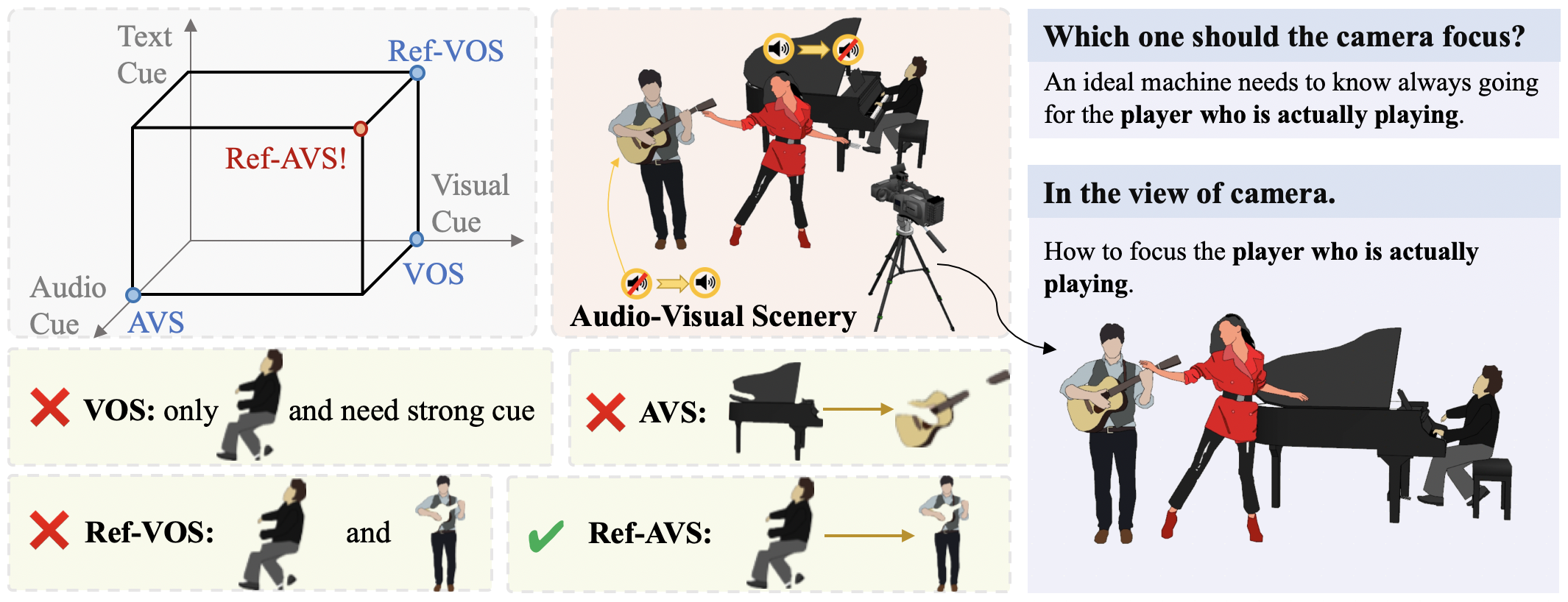
Yaoting Wang*, Peiwen Sun*, Dongzhan Zhou*, Guangyao Li, Honggang Zhang, Di Hu *: equal contribution ECCV, 2024 Arxiv A novel task of referring segmentation by audio, visual, and temporal information. |
|
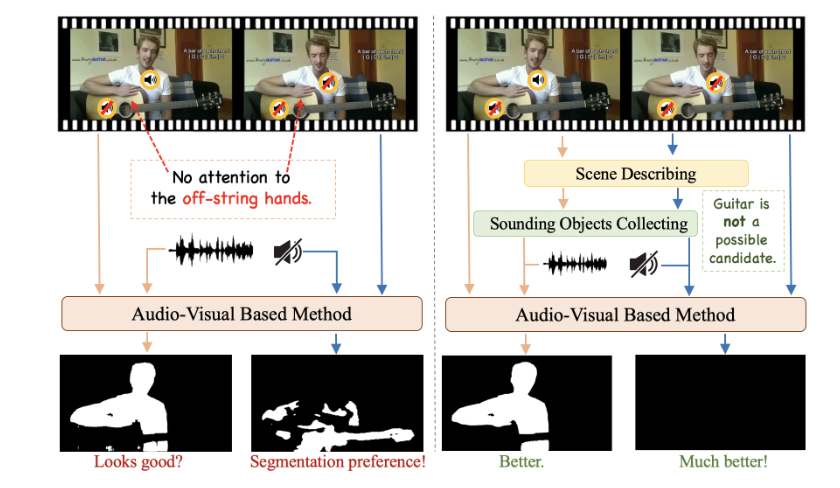
Yaoting Wang*, Peiwen Sun*, Yuanchao Li, Honggang Zhang, Di Hu *: equal contribution ECCV, 2024 Arxiv The ability of LLM can be used to solve segmentation preference on Audio Visual Segmentation. |
|
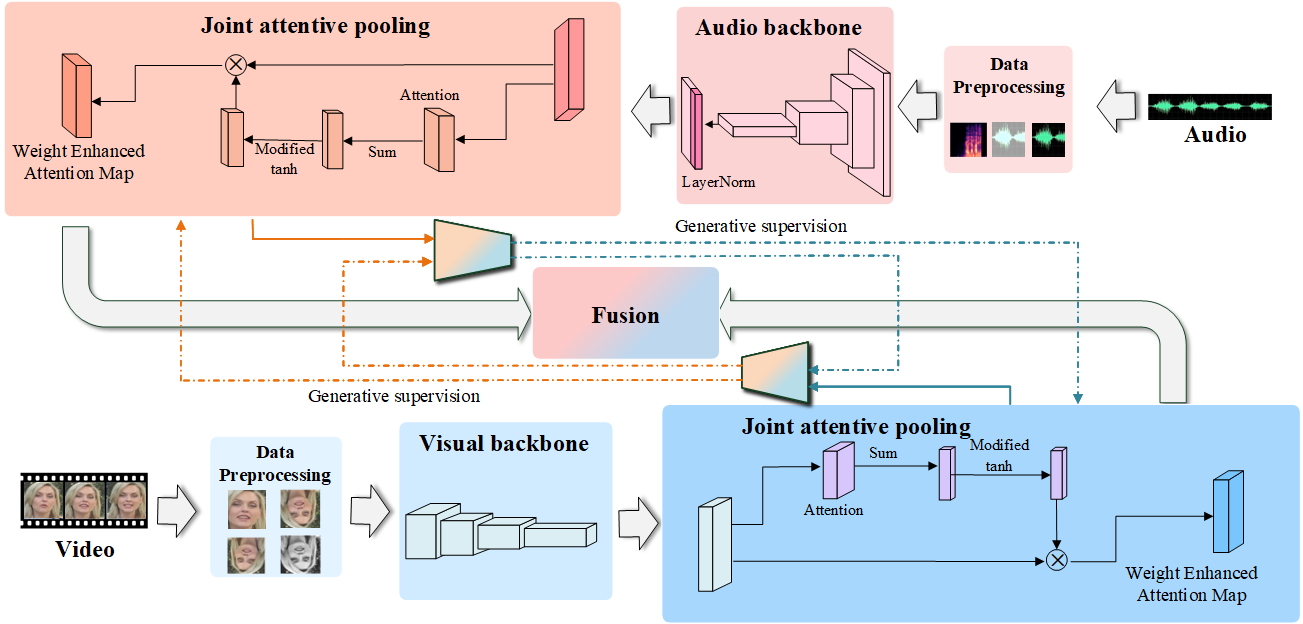
Peiwen Sun, Shanshan Zhang, Zishan Liu, Yougen Yuan, Taotao Zhang, Honggang Zhang, Pengfei Hu INTERSPEECH, 2023 ISCA A novel audio-visual strategy in person verification that considers connections between time series from a generative perspective. |
|
I have been exposed to a variety of research directions such as few-shot learning, medical image processing, mathematical modelling etc. |
|
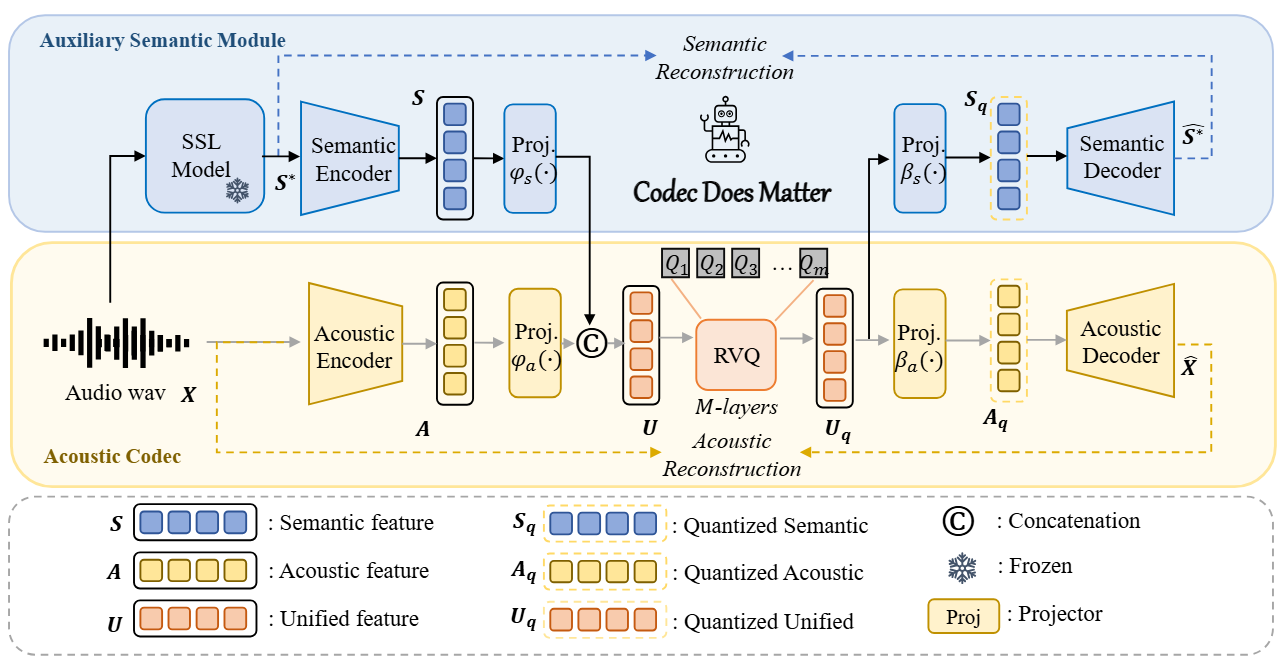
Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, Yike Guo, Wei Xue AAAI, 2024 Arxiv Our research highlights the shortcomings of codecs in current audio LLM, particularly their challenges in maintaining semantic integrity in generated audio. |
|
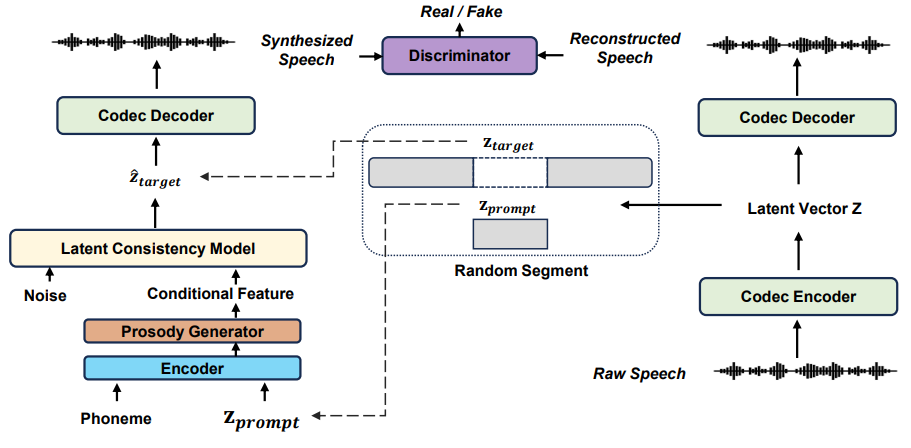
Zhen Ye, Zeqian Ju, Haohe Liu, Xu Tan, Jianyi Chen, Yiwen Lu, Peiwen Sun, Jiahao Pan, Bianweizhen, Shulin He, Wei Xue, Qifeng Liu, Yike Guo ACM MM, 2024 Arxiv A large-scale zero-shot speech synthesis system with approximately 5% of the inference time compared with previous work. |
|
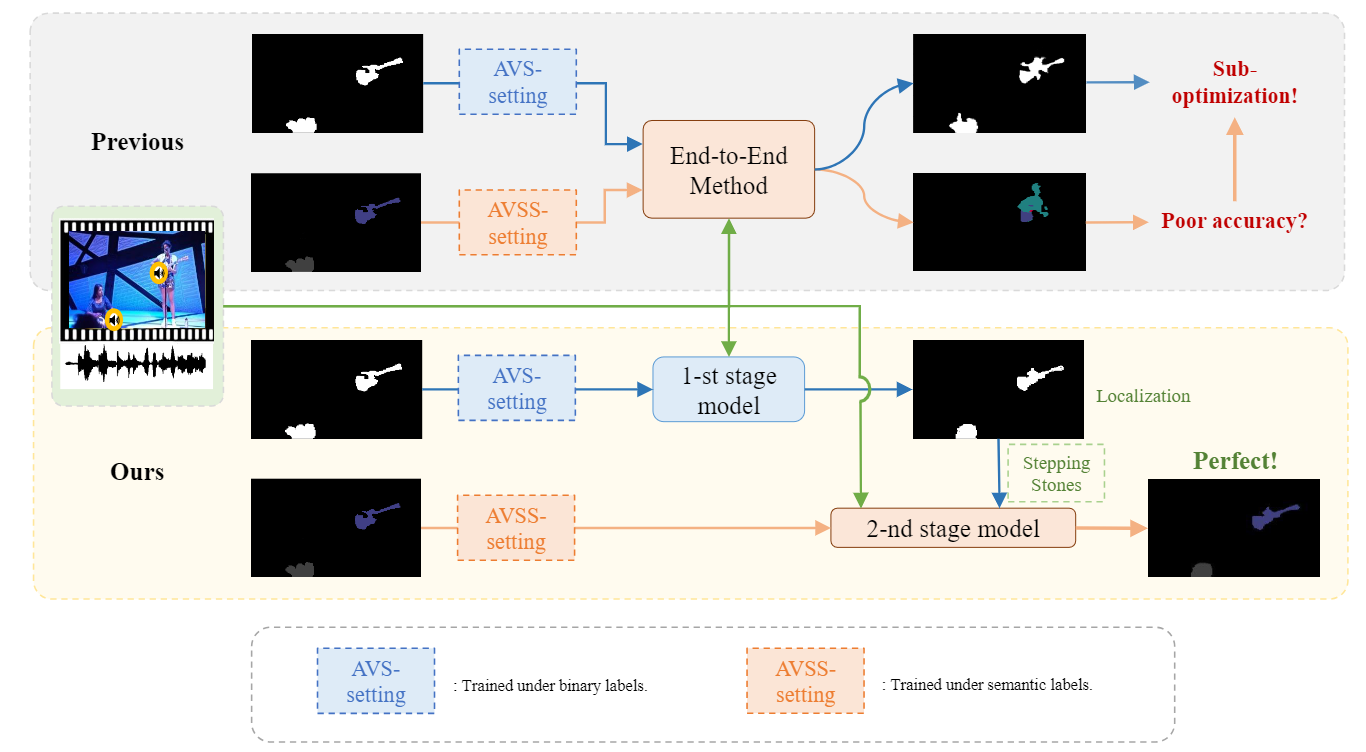
Juncheng Ma, Peiwen Sun, Yaoting Wang, Di Hu ECCV, 2024 Arxiv A two-stage training strategy for AVS, which decomposes the AVSS task into two simple subtasks from localization to semantic understanding, to achieve step-by-step global optimization. |
|
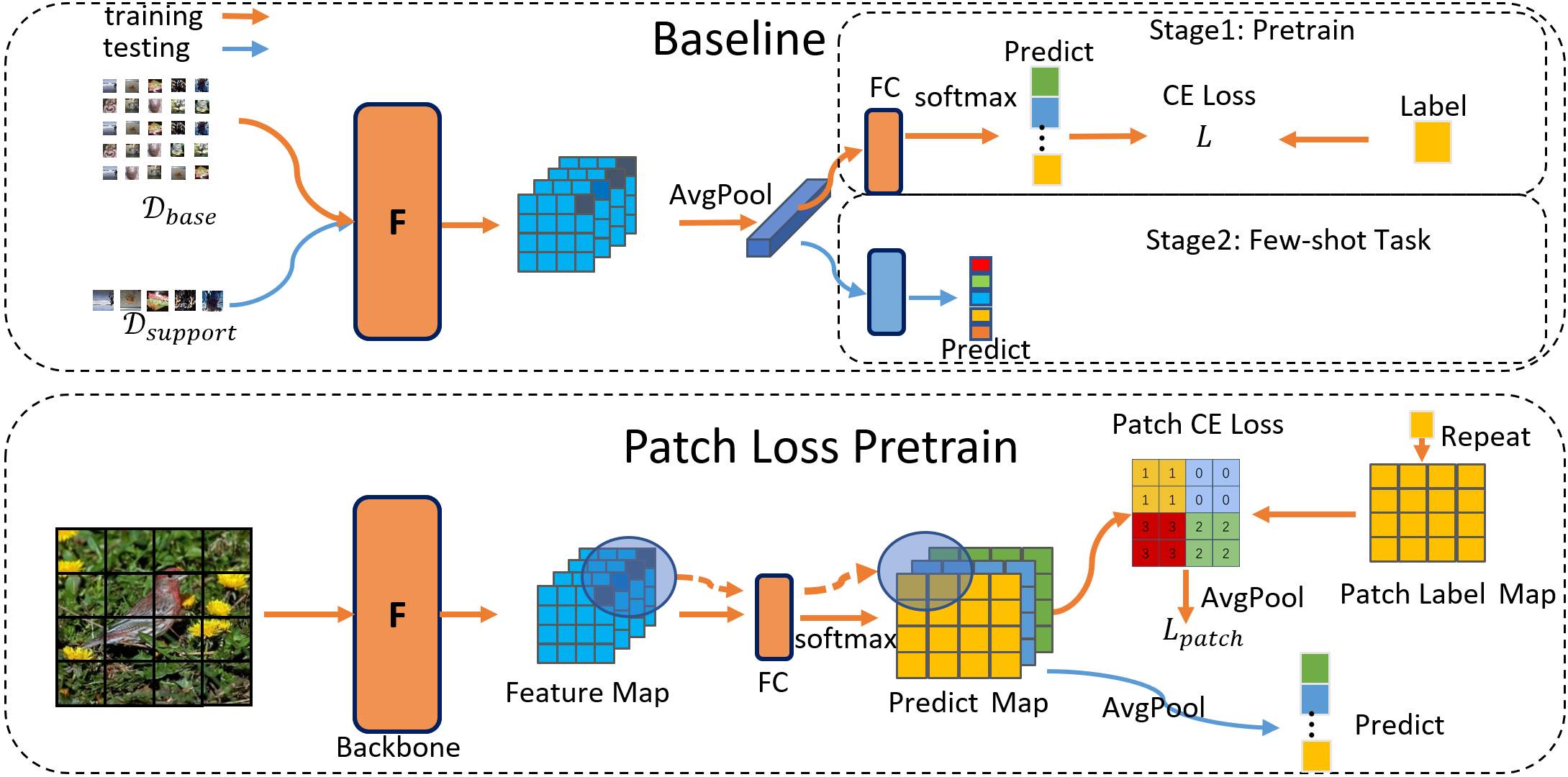
Wangding Zeng*, Peiwen Sun* , Honggang Zhang *: equal contribution IJCNN 2024 IEEE In this paper, we propose a series of strategies to train a better backbone for few-shot learning. |
|
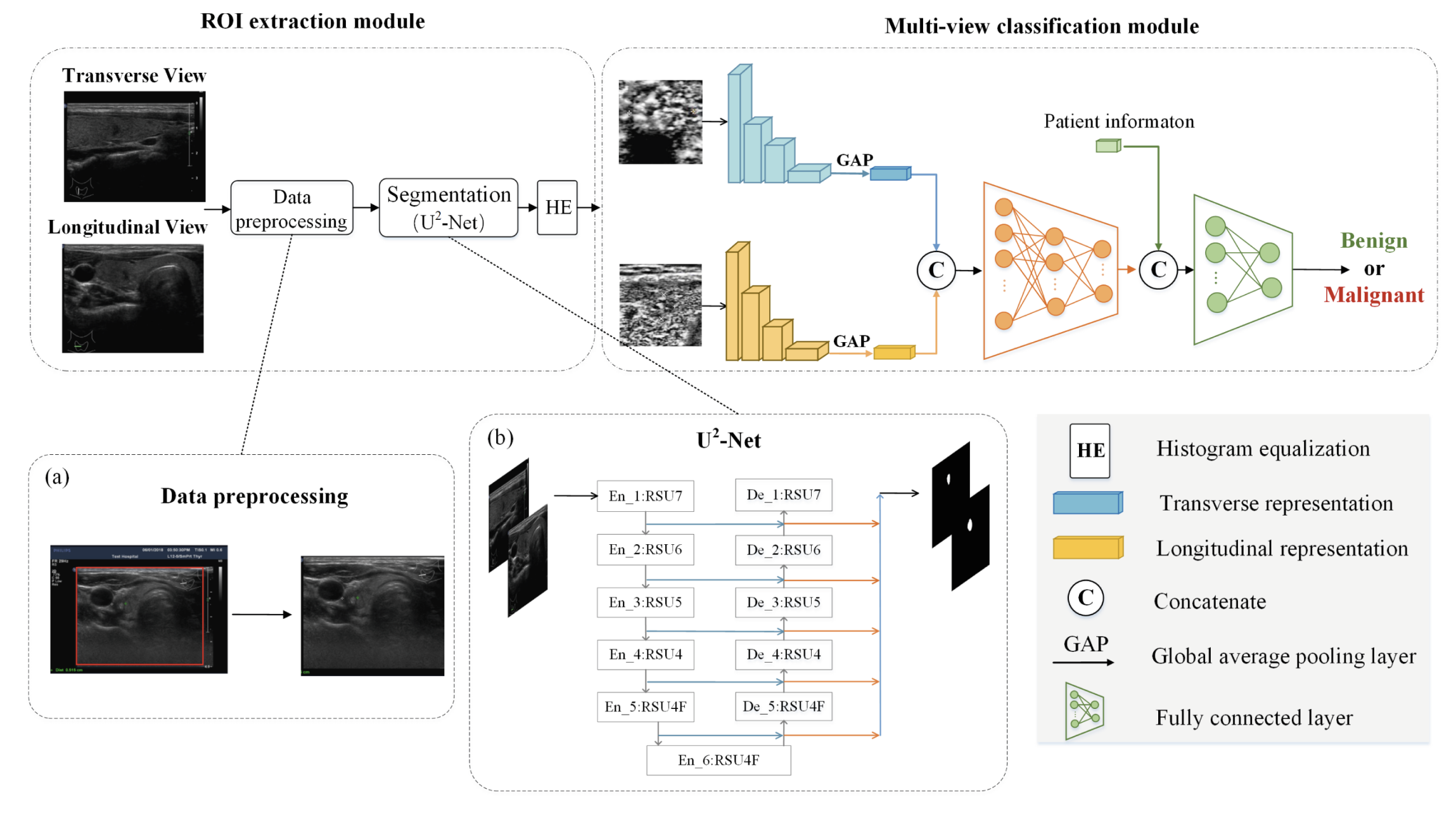
Zishan Liu, Peiwen Sun, Donghao Chen, Honggang Zhang, Yingying Li MICAD 2023 Springer In this paper, the popular semantic segmentation network is firstly applied in thyroid nodule classification in ultrasound images. |

|
Peiwen Sun, Wenjing Ye, Wenqing Yu Mathematical Contest In Modeling, 2021 Finalist Award github A modeling scheme for the layout and number of drones to extinguish and monitor wildfires in southern Australia. |